
“Sardine is Looker for fraud”. At Sardine, we are building the largest fraud and fincrime feature store in the world, to allow fraud and compliance teams the ability to create and backtest new rules in a no-SQL rule editor, using the same advanced post-processed and normalized signals that are used by our AI models. Read this article to learn how we are going about building this.
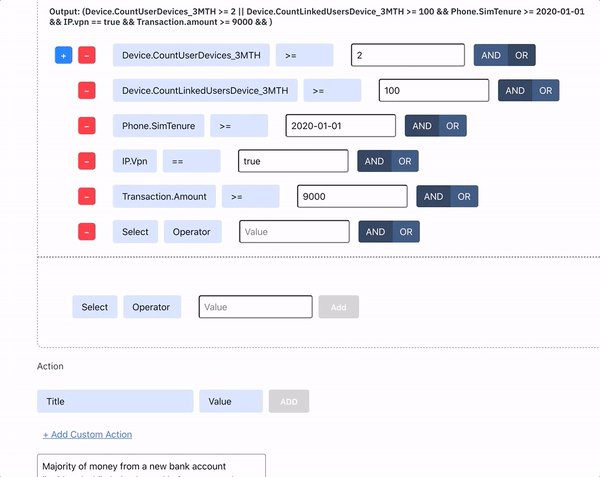
Figure: Sardine’s no-code rule-editor that allows a fraud or compliance analyst to create and backtest new rules with no SQL knowledge. We have 1,000+ features that are all aggregated, post-processed and normalized via a DataFlow job using Apache Beam and Go.
Apache Beam is an open source data processing library. At Sardine we use GCP’s Dataflow as a runner for our beam job to do a variety of data processing.
Our jobs are mostly written in Java since it’s the most well supported by the Apache Beam community. However Beam also supports Python and golang. While Dataflow officially only supports Java and Python, you can still use Dataflow as a runner for your golang job.
We use golang for backend servers, so writing a backfill beam job using golang allowed us to reuse code we use for servers. In this article I will talk about a backfill job that reads the master data from Bigquery, applies some processing with golang and writes to a SQL database.
Given Dataflow does not officially support golang, we couldn’t find many materials online. I hope this article helps someone who wants to achieve similar goals. I assume readers have gone through official getting started and know basic Beam concepts.
If you want to go straight to the source code, here is a link to an open-source repo:
https://github.com/sardine-ai/dataflow-golang-example
The first issue we faced was namespace conflict error caused by the Beam sdk.
panic: proto: file “v1.proto” is already registered
I reported it to the Beam team about a week ago but did not get any response from them. It turns out there is a GOLANG_PROTOBUF_REGISTRATION_CONFLICT flag to ignore conflict so you can just pass it when you run a job locally:
GOLANG_PROTOBUF_REGISTRATION_CONFLICT=warn go run main.go — runner=direct — project=my-gcp-project
For running a job on Dataflow, it’s little more complicated, because Beam SDK implicitly compiles a worker binary for you. Fortunately though, there is a worker_binary flag, so you build your own binary and pass it to Beam:
# build binary for linux with conflictPolicy flag
GOOS=linux GOARCH=amd64 go build -ldflags “-X google.golang.org/protobuf/reflect/protoregistry.conflictPolicy=warn” -o worker_binary .
# then pass it to dataflow
go run main.go \
— runner dataflow \
— worker_binary worker_binary \
...your other flagsFor reading Bigquery, Beam already provides a library so you can just do:
bigqueryio.Query(s, project, “SELECT…”, reflect.TypeOf(SomeData{}))
For writing to database, you can just write your own code. One thing to note is you probably don’t want to keep opening/closing the database connection for each ParDo. You can instead utilize a StartBundle method to initialize database connection. In golang beam, you define struct for ParDo:
// note this stays outside of updateDatabaseFn struct.
// fields in pardo has to be json-serielizable so you cannot have db instance as field
var database *gorm.DB
type updateDatabaseFn struct {
Env string `json:"env"`
Project string `json:"project"`
}
func init() {
beam.RegisterDoFn(reflect.TypeOf((*updateDatabaseFn)(nil)).Elem())
}
// initialize connection here
func (f *updateDatabaseFn) StartBundle(_ctx context.Context) error {
var err error
database, err = initializeDatabase(context.Background(), f.Env, f.Project)
if err != nil {
return errors.Wrap(err, "failed to connect to database")
}
return nil
}
// use your db connection here
func (f *updateDatabaseFn) ProcessElement(ctx context.Context, data SomeData) {
// some data processing here
err := insertRecords(database, data)
// .. more logic hereThat’s it! You can find a simplified code for our job in the below repository.
https://github.com/sardine-ai/dataflow-golang-example
If you are a data geek and enjoyed reading this article, come join us. We are hiring a senior data engineer to help build and scale our Feature Store!